 |
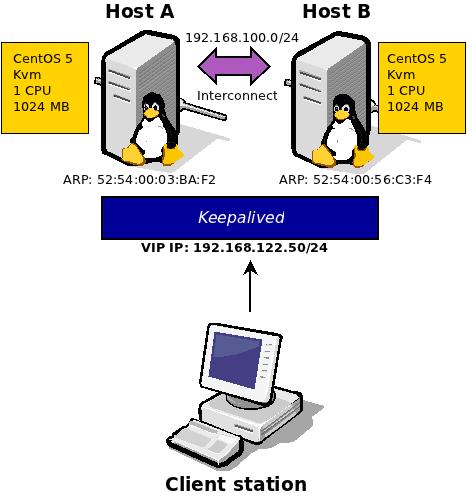
| Figure 1 Deployment diagram of the keepalived for a two node configuration |
In this part there will be two test scenarios described:
- The master goes down (Host A)
- The master starts up again (Host A)
Other cases involving Backup node (Host B) are not relevant to be described in detail since in these cases there is no VIP failover done.
Case A The master goes down (Host A)
Let's first check how the envrionment looks like from the client station perspective. Both nodes (HostA and HostB) are up and running with the keepalived as described in part 1 or this article. The client station is able to ping the VIP address:
krychu@krystianek:~$ ping 192.168.122.50
PING 192.168.122.50 (192.168.122.50) 56(84) bytes of data.
64 bytes from 192.168.122.50: icmp_req=1 ttl=64 time=0.394 ms
64 bytes from 192.168.122.50: icmp_req=2 ttl=64 time=0.353 ms
64 bytes from 192.168.122.50: icmp_req=3 ttl=64 time=0.270 ms
64 bytes from 192.168.122.50: icmp_req=4 ttl=64 time=0.814 ms
^C
--- 192.168.122.50 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 2998ms
rtt min/avg/max/mdev = 0.270/0.457/0.814/0.212 ms
By looking into the arp table:
krychu@krystianek:~$ arp -an
...
? (192.168.122.50) at 52:54:00:03:ba:f2 [ether] on virbr0? (192.168.122.179) at on virbr0
...
we see that the Host A is the one available under the VIP (192.168.122.50) address, which is as we expected it to be since this is the master.
Now let's simulate a crash of the master node as follows:
- We constantly ping the VIP address from the client station
- We simulate a crash of the keepalived process on the master node (Host A), e.g. kill -9
- We check ping output if there was a smooth failover
- We check the ARP table which MAC is used
- We sniff the interface to get the information what caused the client's machine ARP table update
Ok, so what are the results? First of all the node crash does have effect on ICMP packets being dropped - there is a small increase in the response time to about 20.1 ms (please take a look below).
krychu@krystianek:~$ ping 192.168.122.50
PING 192.168.122.50 (192.168.122.50) 56(84) bytes of data.
...
64 bytes from 192.168.122.50: icmp_req=37 ttl=64 time=0.336 ms
64 bytes from 192.168.122.50: icmp_req=38 ttl=64 time=0.398 ms
64 bytes from 192.168.122.50: icmp_req=39 ttl=64 time=0.273 ms
64 bytes from 192.168.122.50: icmp_req=40 ttl=64 time=0.298 ms
64 bytes from 192.168.122.50: icmp_req=41 ttl=64 time=20.1 ms
64 bytes from 192.168.122.50: icmp_req=42 ttl=64 time=0.320 ms
64 bytes from 192.168.122.50: icmp_req=43 ttl=64 time=0.379 ms
64 bytes from 192.168.122.50: icmp_req=44 ttl=64 time=0.314 ms
...
^C
--- 192.168.122.50 ping statistics ---
67 packets transmitted, 67 received, 0% packet loss, time 65997ms
rtt min/avg/max/mdev = 0.198/0.742/20.167/2.472 ms
The proof that the failover has happened can be found in the ARP table - which now has the assignment for the VIP address to the HostB's MAC (previousle Backup keepalived server).
krychu@krystianek:~$ arp -an
...
? (192.168.122.50) at 52:54:00:56:c3:f4 [ether] on virbr0
...
In the wireshark we see that the backup node (HostB) has sent the Gratuitous ARP message to a broadcast MAC announcing that he is the one owning now the VIP address. Afterwards the client station has updated it's ARP cache table.
If we check the keepalived logs on the HostB one can see that after the crash of the HostA has been detected the keepalived is transitioning from the BACKUP to MASTER state:
Sep 11 09:50:49 centOS-hostB Keepalived_vrrp: Using LinkWatch kernel netlink reflector...
Sep 11 09:50:49 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
Sep 11 09:50:49 centOS-hostB Keepalived_vrrp: VRRP sockpool: [ifindex(2), proto(112), fd(10,11)]
Sep 11 10:55:04 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 10:55:05 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 10:55:05 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 10:55:05 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 10:55:10 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 10:55:45 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Received higher prio advert
Sep 11 10:55:45 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
Sep 11 10:55:45 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Sep 11 10:58:35 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 10:58:36 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 10:58:36 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 10:58:36 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 10:58:41 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 11:32:40 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Received higher prio advert
Sep 11 11:32:40 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
Sep 11 11:32:40 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Sep 11 11:39:54 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 11:39:55 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 11:39:55 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 11:39:55 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 11:40:00 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Case B The master is back (Host A)
Now let's focus on the situation when the Host A is brought back after a crash. Just as a reminder the situation is that after a crash HostB took over the Master role, owns the VIP address and the client station has an association to HostB's MAC in its ARP table.
The methodology is similar as in Case A:
- We constantly ping the VIP address from the client station
- We start the keepalived on the HostA
- We check ping output if there was a smooth failover
- We check the ARP table which MAC is used
- We sniff the interface to get the information what caused the client's machine ARP table update
After issuing step 1 and 2 we see again an increase in the response time in the ICMP traffic but much smaller than in case of the crash.
krychu@krystianek:~$ ping 192.168.122.50
PING 192.168.122.50 (192.168.122.50) 56(84) bytes of data.
...
64 bytes from 192.168.122.50: icmp_req=23 ttl=64 time=0.191 ms
64 bytes from 192.168.122.50: icmp_req=24 ttl=64 time=0.346 ms
64 bytes from 192.168.122.50: icmp_req=25 ttl=64 time=0.331 ms
64 bytes from 192.168.122.50: icmp_req=26 ttl=64 time=0.291 ms
64 bytes from 192.168.122.50: icmp_req=27 ttl=64 time=2.53 ms
64 bytes from 192.168.122.50: icmp_req=28 ttl=64 time=0.315 ms
64 bytes from 192.168.122.50: icmp_req=29 ttl=64 time=0.338 ms
...
However it is still not a proof that a failover actually has happened. Let's take a look at the client station's ARP table:
krychu@krystianek:~$ arp -an
...
? (192.168.122.50) at 52:54:00:03:ba:f2 [ether] on virbr0
...
We see that the original mapping (presented in case A), which was pointing to HostB's MAC now points to HostA's. Which indicates the VIP address is now owned by the HostA again. In the wireshark we again see the Gratuitous ARP message to a broadcast MAC announcing sent by the HostA. On this basis the client station has updated it's ARP cache table.
In the logs on HostB one can find the information that after startup of HostA keepalived on HostB is transitioning to BACKUP state since it has received an announcement with a higher priority (review the configuration files from part 1)
Sep 11 10:55:45 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
Sep 11 10:55:45 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Sep 11 10:58:35 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 10:58:36 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 10:58:36 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 10:58:36 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 10:58:41 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 11:32:40 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Received higher prio advert
Sep 11 11:32:40 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
Sep 11 11:32:40 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Sep 11 11:39:54 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 11:39:55 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 11:39:55 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 11:39:55 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 11:40:00 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 11:57:32 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Received higher prio advert
Sep 11 11:57:32 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
Sep 11 11:57:32 centOS-hostB Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Summary
I hope that this exercise gave you a good understaning of the mechanisms controlling the VIP address failover in the keepalived and also some practical knowledge about how to setup such a test environment. For me this activity has been a great experience and fun. I think also it is a good base for further research - about the failure detection mechanisms (happening on the interconnect interface) and providing the application (e.g. HAProxy) on top of keepalived.
Just to summarize the VIP address failover is controlled by a special ARP message (Gratuitous ARP) which has to be accepted and processed by the client station. By processing I mean that the client's station's ARP table mapping have to be updated accordingly.
From the software perspective - the keepalived daemon allows to configure the VIP failover groups and assign MASTER, BACKUP roles for hosts within such a group. There is also a failure detection available which works fast (for a genuine keepalived configuration it was not higher than 20 ms) and controls the VIP address ownership.




Brak komentarzy:
Prześlij komentarz