Let me first remind you the environment configuration- Figure 1.
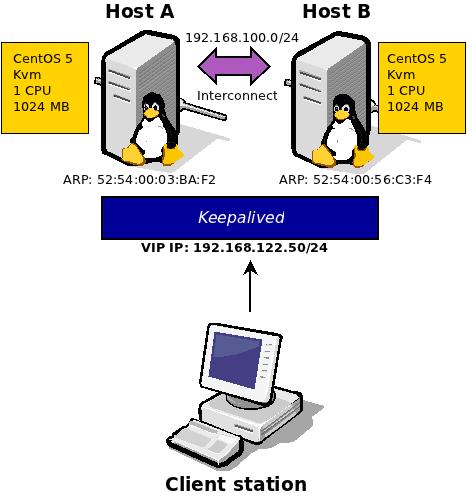 |
| Figure 1 Network deployment of the test environment for the keepalived's VIP failover |
Case C - VIP network interface status monitoring - interface down
What we would like to have is the failover to the BACKUP keepalived node in case something happens to the network interface to which the VIP address is assigned. This feature is supported by the keepalived 1.2.2 but required an enhancement of the configuration file:
[root@centOS-hostA ~]# cat /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 101
track_interface {
eth1
}
virtual_ipaddress {
192.168.122.50/24 brd 192.168.122.255 dev eth1 label eth1:0
}
}
state MASTER
interface eth0
virtual_router_id 51
priority 101
track_interface {
eth1
}
virtual_ipaddress {
192.168.122.50/24 brd 192.168.122.255 dev eth1 label eth1:0
}
}
and the same for the BACKUP node (HostB):
[root@centOS-hostB ~]# cat /etc/keepalived/keepalived.conf
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 51
priority 101
track_interface {
eth1
}
virtual_ipaddress {
192.168.122.50/24 brd 192.168.122.255 dev eth1 label eth1:0
}
}
Where the eth1 is the interface to which the VIP address is assigned to, eth0 stands for the interconnect.
Test methodology:
- We constantly ping the VIP address from the client station
- We simulate a network interface error (we shut it down)
- We check ping output if there was a smooth failover
- We check the ARP table which MAC is used
- We sniff the interface to get the information what caused the client's machine ARP table update
- Check the HostA's log files
krychu@krystianek:~$ arp -na
...
? (192.168.122.50) at 52:54:00:03:ba:f2 [ether] on virbr0
...
...
krychu@krystianek:~$
Now the results. After issuing the first two steps (the interface failure was simulated by ifconfig eth1 down) the keepalived on hostA has changed its status to FAILED and as expected the VIP address has been failed over. However this time one can notice that some ICMP echo replies are lost:
krychu@krystianek:~$ ping 192.168.122.50
PING 192.168.122.50 (192.168.122.50) 56(84) bytes of data.
...
64 bytes from 192.168.122.50: icmp_req=5 ttl=64 time=0.411 ms
64 bytes from 192.168.122.50: icmp_req=6 ttl=64 time=0.376 ms
64 bytes from 192.168.122.50: icmp_req=7 ttl=64 time=0.387 ms
64 bytes from 192.168.122.50: icmp_req=8 ttl=64 time=0.411 ms
64 bytes from 192.168.122.50: icmp_req=13 ttl=64 time=0.532 ms
64 bytes from 192.168.122.50: icmp_req=14 ttl=64 time=0.324 ms
64 bytes from 192.168.122.50: icmp_req=15 ttl=64 time=0.444 ms
...
64 bytes from 192.168.122.50: icmp_req=6 ttl=64 time=0.376 ms
64 bytes from 192.168.122.50: icmp_req=7 ttl=64 time=0.387 ms
64 bytes from 192.168.122.50: icmp_req=8 ttl=64 time=0.411 ms
64 bytes from 192.168.122.50: icmp_req=13 ttl=64 time=0.532 ms
64 bytes from 192.168.122.50: icmp_req=14 ttl=64 time=0.324 ms
64 bytes from 192.168.122.50: icmp_req=15 ttl=64 time=0.444 ms
...
^C
--- 192.168.122.50 ping statistics ---
22 packets transmitted, 18 received, 18% packet loss, time 20997ms
rtt min/avg/max/mdev = 0.295/0.408/0.683/0.088 ms
krychu@krystianek:~$ arp -na
...
--- 192.168.122.50 ping statistics ---
22 packets transmitted, 18 received, 18% packet loss, time 20997ms
rtt min/avg/max/mdev = 0.295/0.408/0.683/0.088 ms
krychu@krystianek:~$ arp -na
...
? (192.168.122.50) at 52:54:00:56:c3:f4 [ether] on virbr0
...
...
The information about transition can be found in the logs:
Sep 11 19:09:45 centOS-hostA Keepalived: Starting VRRP child process, pid=3411
Sep 11 19:09:45 centOS-hostA Keepalived_vrrp: Opening file '/etc/keepalived/keepalived.conf'.
Sep 11 19:09:45 centOS-hostA Keepalived_vrrp: Configuration is using : 63057 Bytes
Sep 11 19:09:45 centOS-hostA Keepalived_vrrp: Using LinkWatch kernel netlink reflector...
Sep 11 19:09:45 centOS-hostA Keepalived_vrrp: VRRP sockpool: [ifindex(2), proto(112), fd(10,11)]
Sep 11 19:09:46 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 19:09:52 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: Kernel is reporting: interface eth1 DOWN
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering FAULT STATE
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Now in FAULT state
Case D - VIP network interface status monitoring - interface up
Now let's simulate that the network interface on HostA is brought back (by executing the ifconfig eth1 up).
As one can see there is nothing to be noticed in the ICMP echo replies, also client's station's ARP table entry remained unchanged.
krychu@krystianek:~$ ping 192.168.122.50
PING 192.168.122.50 (192.168.122.50) 56(84) bytes of data.
64 bytes from 192.168.122.50: icmp_req=1 ttl=64 time=3.57 ms
64 bytes from 192.168.122.50: icmp_req=2 ttl=64 time=0.446 ms
64 bytes from 192.168.122.50: icmp_req=3 ttl=64 time=0.387 ms
64 bytes from 192.168.122.50: icmp_req=4 ttl=64 time=0.374 ms
64 bytes from 192.168.122.50: icmp_req=5 ttl=64 time=0.395 ms
64 bytes from 192.168.122.50: icmp_req=6 ttl=64 time=0.368 ms
64 bytes from 192.168.122.50: icmp_req=7 ttl=64 time=0.571 ms
64 bytes from 192.168.122.50: icmp_req=8 ttl=64 time=0.288 ms
64 bytes from 192.168.122.50: icmp_req=9 ttl=64 time=0.380 ms
64 bytes from 192.168.122.50: icmp_req=10 ttl=64 time=0.371 ms
64 bytes from 192.168.122.50: icmp_req=11 ttl=64 time=0.353 ms
64 bytes from 192.168.122.50: icmp_req=12 ttl=64 time=0.359 ms
64 bytes from 192.168.122.50: icmp_req=13 ttl=64 time=0.387 ms
64 bytes from 192.168.122.50: icmp_req=14 ttl=64 time=0.367 ms
64 bytes from 192.168.122.50: icmp_req=15 ttl=64 time=0.366 ms
^C
--- 192.168.122.50 ping statistics ---
15 packets transmitted, 15 received, 0% packet loss, time 14000ms
rtt min/avg/max/mdev = 0.288/0.599/3.579/0.798 ms
krychu@krystianek:~$ arp -na
...
PING 192.168.122.50 (192.168.122.50) 56(84) bytes of data.
64 bytes from 192.168.122.50: icmp_req=1 ttl=64 time=3.57 ms
64 bytes from 192.168.122.50: icmp_req=2 ttl=64 time=0.446 ms
64 bytes from 192.168.122.50: icmp_req=3 ttl=64 time=0.387 ms
64 bytes from 192.168.122.50: icmp_req=4 ttl=64 time=0.374 ms
64 bytes from 192.168.122.50: icmp_req=5 ttl=64 time=0.395 ms
64 bytes from 192.168.122.50: icmp_req=6 ttl=64 time=0.368 ms
64 bytes from 192.168.122.50: icmp_req=7 ttl=64 time=0.571 ms
64 bytes from 192.168.122.50: icmp_req=8 ttl=64 time=0.288 ms
64 bytes from 192.168.122.50: icmp_req=9 ttl=64 time=0.380 ms
64 bytes from 192.168.122.50: icmp_req=10 ttl=64 time=0.371 ms
64 bytes from 192.168.122.50: icmp_req=11 ttl=64 time=0.353 ms
64 bytes from 192.168.122.50: icmp_req=12 ttl=64 time=0.359 ms
64 bytes from 192.168.122.50: icmp_req=13 ttl=64 time=0.387 ms
64 bytes from 192.168.122.50: icmp_req=14 ttl=64 time=0.367 ms
64 bytes from 192.168.122.50: icmp_req=15 ttl=64 time=0.366 ms
^C
--- 192.168.122.50 ping statistics ---
15 packets transmitted, 15 received, 0% packet loss, time 14000ms
rtt min/avg/max/mdev = 0.288/0.599/3.579/0.798 ms
krychu@krystianek:~$ arp -na
...
? (192.168.122.50) at 52:54:00:56:c3:f4 [ether] on virbr0
...
krychu@krystianek:~$ ...
So what has happened? The answer can be found in the logs:
Sep 11 19:09:46 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 19:09:52 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: Kernel is reporting: interface eth1 DOWN
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering FAULT STATE
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Now in FAULT state
Sep 11 21:00:50 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
The HostA's keepalived has changed the state from FAULTY to BACKUP and HostB remained the MASTER. It loks strange and not consistent with the node failure/recovery transitions but let's try to shutdown the HostB now and see if HostA will transistion into MASTER.
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 19:09:47 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 19:09:52 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: Kernel is reporting: interface eth1 DOWN
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering FAULT STATE
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) removing protocol VIPs.
Sep 11 20:55:37 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Now in FAULT state
Sep 11 21:00:50 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering BACKUP STATE
Sep 11 21:06:15 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Transition to MASTER STATE
Sep 11 21:06:16 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Entering MASTER STATE
Sep 11 21:06:16 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) setting protocol VIPs.
Sep 11 21:06:16 centOS-hostA Keepalived_vrrp: VRRP_Instance(VI_1) Sending gratuitous ARPs on eth1 for 192.168.122.50
As expected - after shutdown of HostB, HostA took over the role of MASTER and send the gratuitous ARP to update client station's ARP table. So the HA is provided but it still looks a bit inconsistent compared to the other scenarios
Summary
Although I did not check all scenarios related to the network problems - it seems that keepalived provides good support for monitoring the network interface. In the doc/samples/(...)track_interface file one can also find examples how to monitor multiple network interfaces.




